FINS Faculty are currently conducting sponsored research on the following Artificial Intelligence (AI) topics:
A note on AI and National Defense: Intelligence implies the ability to learn and utilize knowledge to perform a task. Human intelligence–considered the epitome–enabled mankind to thrive. Artificial Intelligence (AI) attempts to impart this ability to computer algorithms in performing a chosen task effectively. AI can acquire information from a wide variety of sources simultaneously and retain or recall knowledge indefinitely. It can also be sensitive to minute changes in data otherwise imperceptible to humans, while simultaneously understanding latent relationships in said data. Insights obtained from AI have been used to expand human understanding. With these characteristics combined with lack of boredom and fatigue, the ability to surpass human capabilities at a fraction of the effort comes as no surprise. Hence, AI is not only an ideal candidate for national security applications but a necessity in ensuring robust and reliable mission critical systems.
AI for Security-Aware Electronics:
Over the last 35 years, the EDA industry has delivered improvements in chip design productivity 10 million times. With Moore’s Law ending, most experts agree that chips designed by AI and Machine Learning (ML) are the future of semiconductors. In fact, academic and commercial tools are now starting to incorporate AI/ML for optimization of digital and analog integrated circuits (ICs) at various levels of abstraction in very large solution spaces. However, the goals thus far have been to enhance traditional metrics such as power, performance, and area. Security concerns and issues related to IC design have been highly overlooked.
A current thrust at FINS is investigating state-of-the-art methods in AI/ML to optimize and port hardware security primitives such as physical unclonable functions (PUFs), true random number generators (TRNGs), and silicon odometers across technology nodes to predict functionality-security-performance tradeoffs and guide users/tools, seamlessly integrate best-in-class protections (e.g., masking, hiding, fault tolerance, etc.) under traditional constraints, and to harden designs/layouts against hardware Trojans and Intellectual Property (IP) theft. Furthermore, we are exploring the benefits of federated learning to overcome data bottlenecks while effectively utilizing AI/ML without compromising the confidentiality of semiconductor IP.
Artificial Scientific Intelligence for Automating Scientific Modeling:
 The explosive growth of diversified data has reaped unprecedented advancements in scientific discovery and engineering. Unfortunately, it is difficult to relate data from one problem to another without a unified approach to the mathematics of scientific modeling. FINS researcher James Fairbanks takes a radical approach to scientific computing that applies category theory to mathematically model mathematics itself. This novel approach is the foundation of the software for diverse scientific applications including space weather forecasting to protect satellite communications, and the hierarchical analysis and control of immunology and epidemics. Both areas are of vital interest to the science portfolio of DARPA, the research and development agency of the Department of Defense (DoD). FINS uses category theory, a mathematical language developed to unify the diverse fields and subfields of mathematics, to create a software ecosystem that unifies the various fields and subfields of computational science and engineering. Dr. Fairbanks’ team specializes in taking this lofty abstract language and implementing concrete software packages that solve real-world problems for stakeholders.
The explosive growth of diversified data has reaped unprecedented advancements in scientific discovery and engineering. Unfortunately, it is difficult to relate data from one problem to another without a unified approach to the mathematics of scientific modeling. FINS researcher James Fairbanks takes a radical approach to scientific computing that applies category theory to mathematically model mathematics itself. This novel approach is the foundation of the software for diverse scientific applications including space weather forecasting to protect satellite communications, and the hierarchical analysis and control of immunology and epidemics. Both areas are of vital interest to the science portfolio of DARPA, the research and development agency of the Department of Defense (DoD). FINS uses category theory, a mathematical language developed to unify the diverse fields and subfields of mathematics, to create a software ecosystem that unifies the various fields and subfields of computational science and engineering. Dr. Fairbanks’ team specializes in taking this lofty abstract language and implementing concrete software packages that solve real-world problems for stakeholders.
Automated Physical Inspection for Counterfeit Electronics Detection and Avoidance:
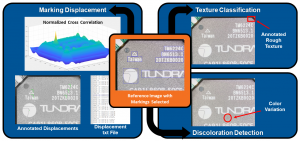
Counterfeit electronics in the supply chain are a longstanding issue with nontrivial impacts on government, industry, and society as a whole: (i) security and reliability risks for critical systems and infrastructures that incorporate them; (ii) substantial economic losses for IP owners; (iii) source of revenue for terrorist groups and organized crime; (iv) reduce the incentive to develop new products and ideas, thereby impacting worldwide innovation, economic growth, and employment. The counterfeit chip market has an estimated worldwide value of $75B, and such chips are then integrated into electronic devices reportedly worth more than $169. The ongoing chip shortage due to the COVID-19 pandemic exacerbates the situation by creating huge gaps in the supply chain.
FINS is currently engaged in research that focuses on using AI, image processing, and computer vision to address the challenges associated with non-invasive physical inspection for counterfeit integrated circuit (IC) and printed circuit board (PCB) detection. Namely, by automating identification of the defects associated with counterfeits, we can reduce the time, costs, and need for subject matter experts. This technology is envisioned for use by non-technical, minimally trained operators such as border agents at U.S. Ports of Entry.
Authorship Attribution:

Every literary piece has a unique style composition. Addition of this style element to the text transforms the raw information into an artwork. In authorship attribution, this style is considered the author’s virtual fingerprint and is present in every text article composed by the author. There are several situations in everyday life where the author of a document needs to be identified, such as with the Federalist Papers where the authors are unknown or the authorship is in dispute, or in forensic situations where the authenticity of a suicide note needs to be verified. Even in present-day cyberspace, the inherent anonymity is exploited to publish text articles of sensitive nature ranging from hate speech to fake news. Stylistic analysis can effectively assist in these situations by identifying the author of the text article.
Another ongoing thrust at FINS focuses on leveraging natural language processing, machine learning, and artificial intelligence to process, identify, and extract stylistic information from the text. This information is later utilized in matching an unknown document to its author and, by extension, even obtain heuristics on the author’s physical and psychological state.
Computational Behavioral Analytics:

Psychology suggests that an individual’s language usage is conditioned by their life experiences and, consequently, reflects their personality. Inferring an individual’s personality traits from their language usage can then be used to predict behavior. Since individuals modulate their language based on all accumulated life experiences, identifying markers for the desired traits need to be manually isolated for analysis. Well-established personality models–such as Big5, MBTI, and Dark Triad–measure using carefully curated psychological questionnaires that help probe personality traits. The inherent relationship with language then provides an avenue for passive assessment of these traits. The ability to predict behavior from personality traits can be used for psychological profiling in both medical and forensic settings, as well as commercial.
Grounded in psychology and linguistics, research on this topic by FINS aims to enhance the current state of behavior analysis from uncontrolled raw text samples to enable human interpretation and leverage recent advances in natural language processing/inferencing along with machine learning and artificial intelligence.
FakeNews: Modeling the neurocognitive mechanisms underlying fake news detection using AI:
 Fabricated information mimicking news media, referred to as “fake news”, is an epidemic deception technique to manipulate public opinion. Older adults, and especially those with lower cognitive functioning, are particularly vulnerable to deception via fake news. Currently only technical solutions exist (e.g. fact checking), but fake news continues to break through, leaving human decision making as the last line of defense. A FINS research team, which includes psychology professors, are working on developing a neural network model to identify deceptive features in news headlines and cognitive characteristics in the decision maker toward enhancing fake news detection.
Fabricated information mimicking news media, referred to as “fake news”, is an epidemic deception technique to manipulate public opinion. Older adults, and especially those with lower cognitive functioning, are particularly vulnerable to deception via fake news. Currently only technical solutions exist (e.g. fact checking), but fake news continues to break through, leaving human decision making as the last line of defense. A FINS research team, which includes psychology professors, are working on developing a neural network model to identify deceptive features in news headlines and cognitive characteristics in the decision maker toward enhancing fake news detection.
Cyber Deception for Proactive Defense Against Physical Attacks:

Modern system-on-chip circuits (SoCs) handle sensitive assets like keys, proprietary firmware, top secret data, etc. Attacks against SoCs may arise from malicious or vulnerable software, the hardware itself (e.g., hardware Trojans), and physical attacks against hardware (side channel analysis, fault injection, optical probing, microprobing, and circuit edit). Recently, cyber-attacks that exploit physical vulnerabilities have been successfully performed against commercial chips, e.g., to remotely extract keys from TrustZone in ARM/Android devices, to breach confidentiality and integrity of Intel SGX and AMD SEV, and more. These exploits demonstrate that existing solutions are not enough. Further, given the static and long-lived nature of hardware, it can be argued that compromise by physical attacks is inevitable.
One thrust of FINS’s research on this topic aims to address hardware vulnerabilities to physical attacks using cyber deception. Cyber deception is an emerging proactive methodology that tries to reverse the typical asymmetry in cybersecurity where the attacker alters at will while the defender is a “sitting duck”. Specifically, FINS utilizes deception to enable chip designers to gather intelligence on attacks/attackers, assess their exploitive capabilities, and perform self-aware manipulation that forces them to waste valuable time and resources during attacks. In the long term, AI and Game Theory will be used to craft optimal hardware deception policies.
Phishing: Identifying vulnerabilities to cyber deception by simulating phishing attacks:

Another example of a form of cyber-attack currently being researched by FINS faculty involves Phishing, which steals sensitive information and targets hardware systems via viruses in deceptive messages (e.g., emails, phone texts). One of FINS’s research teams is working on a project where simulated Phishing emails and text messages are sent to study participants to determine their susceptibility to this form of deception. Results have shown that older (compared to younger) adults, particularly those with low positive affect and low cognitive function, are at risk for falling for Phishing attacks. New knowledge generated from this project will inform defense solutions in reducing vulnerability to cyber-deception in adults of different ages; and will enhance the design of real-world experimental Phishing interventions for use in future research.
Data Augmentation:
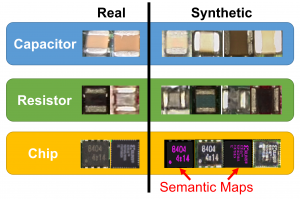
A significant barrier in data-driven analysis, especially deep learning, is the lack of data. In microelectronics security, the development of pre-silicon assessment tools and post-silicon assistance tests requires lots of real-world test articles, benchmarks, measurements, and datasets. The obvious advantage of real examples is that they have security vulnerabilities already identified, e.g. CVEs in the National Vulnerability Database. However, such designs are typically confidential, proprietary, or difficult to share. Additionally, collecting images and/or measurements from real-world systems can be time consuming and expensive. This has led most researchers to rely on open-source data, which is also limited.
In one of FINS’s thrusts on this topic, we focus on generating arbitrarily large amounts of synthetic test articles and benchmarks using data augmentation–a technique used to increase the amount of data by adding slightly modified copies of already existing data. For example, in the image domain, we are employing Generative Adversarial Networks (GANs) and semantic maps to create realistic optical and Scanning Electron Microscope (SEM) images for counterfeit detection, hardware Trojan detection, etc. At the circuit level, FINS is creating diverse test articles and benchmarks using a mixture of parameter variation, traditional optimization, and AI-based optimization.
Deepfakes:
 Deepfake refers to data generated by a deep learning model based on a fictitious scenario. The data can be of any form ranging from image, audio, to even video. With the current state-of-the-art deepfake models, it is possible to synthesize highly deceitful content that can be indistinguishable from authentic content. Such content is always tied to ethical issues or concerns because they are widely used for blackmailing, creating fake news, or fake pornography videos. Generative models are hazardous in the wrong hands, but they still have some highly sought-after positive applications. One such application is synthetic data generation. Generative models can synthesize different types of data that can assist in providing insights into experiments that may never occur in real-life.
Deepfake refers to data generated by a deep learning model based on a fictitious scenario. The data can be of any form ranging from image, audio, to even video. With the current state-of-the-art deepfake models, it is possible to synthesize highly deceitful content that can be indistinguishable from authentic content. Such content is always tied to ethical issues or concerns because they are widely used for blackmailing, creating fake news, or fake pornography videos. Generative models are hazardous in the wrong hands, but they still have some highly sought-after positive applications. One such application is synthetic data generation. Generative models can synthesize different types of data that can assist in providing insights into experiments that may never occur in real-life.
FINS’s thrust on this topic focuses on imbuing the deep learning models with the ability to better understand/interpret the exemplary data and gain finer control over the data generation process.
Delineating psychological correlates of deepfake detection
 One FINS research team is currently working towards the examination the human factors involved in deepfake detection. The main areas of investigation include, but are not limited to, determining how well humans can detect faces in deepfake images and videos as well as examining the role of various psychological and cognitive processes on detection of deepfakes. In this context, the teams are also interested in understanding how human performance compares to machine (classification algorithm) performance in deepfake face detection.
One FINS research team is currently working towards the examination the human factors involved in deepfake detection. The main areas of investigation include, but are not limited to, determining how well humans can detect faces in deepfake images and videos as well as examining the role of various psychological and cognitive processes on detection of deepfakes. In this context, the teams are also interested in understanding how human performance compares to machine (classification algorithm) performance in deepfake face detection.
Explainable Artificial Intelligence:
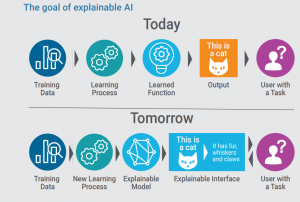 As AI solutions become ever more ubiquitous, there is still a serious lack of understanding in how these systems make decisions. The brittle nature of the statistical correlations learned by these models are often overlooked. To address this gap, Explainable and Interpretable Artificial Intelligence (XAI) research seeks to explain how and why models make their decisions. Without this understanding, users of AI systems are left blindly trusting the output of their AI models. Especially in high-stakes decision-making such as with self-driving cars and criminal sentencing, XAI methods provide trust anchors in how these systems work in order to verify the validity of these decisions and debug them when they are not.
As AI solutions become ever more ubiquitous, there is still a serious lack of understanding in how these systems make decisions. The brittle nature of the statistical correlations learned by these models are often overlooked. To address this gap, Explainable and Interpretable Artificial Intelligence (XAI) research seeks to explain how and why models make their decisions. Without this understanding, users of AI systems are left blindly trusting the output of their AI models. Especially in high-stakes decision-making such as with self-driving cars and criminal sentencing, XAI methods provide trust anchors in how these systems work in order to verify the validity of these decisions and debug them when they are not.
One of FINS faculty’s thrust on this topic focuses on interpretable methods for natural language processing. We distinguish traditional XAI and inherently interpretable AI architectures. XAI has primarily focused on post-hoc, opaque-box approaches, which can be misleading as they themselves are approximations of the model they are attempting to explain. This work focuses on the design of powerful inherently interpretable methods that combine the clarity of decision trees with the power of deep learning neural architectures.
Integrated Formal Methods & Game Theory for Security:

For mission-critical Cyber-Physical Systems (CPSs), it is crucial to ensure these systems behave correctly while interacting with dynamic, and potentially adversarial environments. Synthesizing CPSs with assurance is a daunting task. On the one hand, the interconnected networks, sensors, and (semi-)autonomous systems introduce unprecedented vulnerabilities to both cyber- and physical spaces; on the other hand, purposeful and deceptive attacks may aim to compromise more complex system properties beyond traditional stability and safety. FINS aims to develop integrated formal methods and Game Theory for constructing provably correct and secure cyber-physical systems.
Inverse Reinforcement Learning:
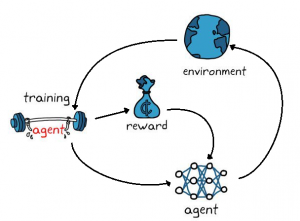
Reinforcement Learning (RL) is a machine learning paradigm inspired by how humans learn. In RL, algorithms called “agents” interact with a simulated environment. In turn, the simulated environment provides feedback to the agent based on what actions it takes. The RL agent continues taking actions and the environment continues providing feedback until the RL agent optimizes a task. Hence, RL has achieved high performances in applications where one’s actions have consequences, and those consequences may be delayed in time. Examples of applications where RL has been successfully deployed include self-driving vehicles, automated stock trading, customized healthcare, robot manipulation, and natural language processing.
Current research on this topic at FINS concerns Inverse Reinforcement Learning (IRL), which is the opposite of RL. While RL involves designing agents that optimize some task, IRL involves designing algorithms that understand said agents. IRL helps humans infer how RL agents operate, what they are doing, and what they will do next. IRL has many applications within the domain of human-computer interaction, such as human interpretability of agents and efficient agent training from human experts.
Machine Learning (ML):

Automated Scene Understanding:
Automated scene understanding is the task of being able to automatically describe a scene (algorithmically) given input data and imagery. Many scene understanding approaches in the machine learning literature rely on semantic segmentation approaches which require precise, detailed label information for a large body of training imagery. Yet this data is often difficult, if not infeasible, to obtain. Furthermore, most semantic segmentation approaches can only learn crisp segmentations of a scene and are incapable of describing regions of transition or gradients. FINS has ongoing studies for developing and implementing semi-supervised learning approaches that can use all available information about a scene and mitigate the need for large, precise training sets. Geo-tagged social media data, map data, analyst key-points, and any available ground-truth or scene information are used to guide this analysis. This type of ancillary data provides scene information that can be leveraged during hyperspectral analysis. However, this data is likely to be noisy, incomplete, or inaccurately registered. FINS is developing a framework and algorithms for semi-supervised multi- sensor fusion that can learn from imprecise labels. FINS is also developing soft segmentation approaches that can identify and describe gradients and regions of transitions in input imagery. This will allow for automated understanding of a wider range and more realistic scenarios than previously possible.
Target Characterization from Uncertain Labels:
Most supervised Machine Learning algorithms assume that each training data point is paired with an accurate training label. However, obtaining accurate training label information is often times consuming and expensive. Human annotators may be inconsistent when labeling a data set, providing inherently imprecise label information. Training an accurate classifier or learning a representative target signature from this sort of uncertainly labeled training data is extremely difficult in practice. FINS is developing approaches that can perform target characterization even with this uncertainty. Target characterization learns characteristic, salient features for targets of interest which can then be used in detection applications. Research in this area provides practical methods that allow application of machine learning methods to problems that were previously bottle-necked by ground-truth requirements needed by traditional machine learning approaches.
Natural Language Processing (NLP):
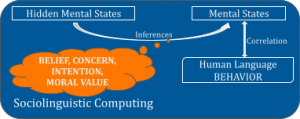 Discovery of hidden mental states using explanatory language representations:
Discovery of hidden mental states using explanatory language representations:
Taking the pulse of a given population in a health crisis (such as a pandemic) may predict how the public will handle restrictive situations and what actions need to be taken/promoted in response to emerging attitudes. Our research focuses on the use of explainable representations to gauge potential reactions to non-pharmaceutical interventions (such as masks) through NLP techniques to discover hidden mental states. A stance, which is a belief-driven sentiment, is extracted via propositional analysis (i.e., I believe masks do not help [and if that belief were true, I would be antimask]), instead of a bag-of-words lexical matching or an embedding approach that produces a basic pro/anti label. For example, the sentence I believe masks do not protect me is rendered as ~PROTECT(mask,me). We pivot off this explanatory representation to answer questions such as What is John’s underlying belief and stance towards mask wearing? Because a health crisis can lead to drastic global effects, it has become increasingly important to derive a sense of how people feel regarding critical interventions, especially as trends in online activity may be viewed as proxies for the sociological impact of such crises.
 Natural Language Processing (NLP) across languages and cultures:
Natural Language Processing (NLP) across languages and cultures:
Speakers of different languages express content differently, both due to language divergences (e.g., Chinese word order indicates grammatical meaning, whereas Korean relies heavily on suffixes for grammatical meaning) and cultural distinctions (e.g., discussions about a given topic may employ conformist or polite terms in one culture, but may employ emotive or antagonistic terms in another). FINS’s multilingual and multicultural NLP takes into account such distinctions for both analysis and synthesis of human language for a wide range of applications of interest to national security, including the detection of beliefs, stances, or concerns associated with heavily debated topics that might lead to harmful polarization or violence. Mapping NLP algorithms across languages and cultures and understanding both equivalences and distinctions among syntactic, lexical, and semantic levels of understanding is a key component toward supporting civil discourse across languages and cultures.
 NLP in Social Media vis a vis Minority & Gender Representation:
NLP in Social Media vis a vis Minority & Gender Representation:
Extensive use of online media comes with its own set of problems. One of the significant problems plaguing online social media is rampant mis/disinformation and the use of toxic language to silence minorities. Dr. Oliveira’s team uses AI and NLP to understand and attempt to predict human behavior. The techniques employed aim to identify what features personality are more likely to be associated with higher user engagement in deceptive Facebook posts and to understand misinformation on social media platforms, such as Twitter, as a function of tweet engagement, content, and veracity. They also study methods to identify subtle toxicity (e.g., benevolent sexism, sarcasm, etc.) in online conversations. The ability to identify these markers of engagement and harmful behavior can be used to build better systems that can shield people online. Besides studying social media, Dr. Oliveira’s team also looks into online news media. They use NLP to explore factors associated with gender bias and to identify influence cues of disinformation in news media texts. Further, AI is used to identify temporal features of users’ behaviors that can be used to distinguish them online. A particular research thrust showed that online users have unique computer usage behaviors which can be used to distinguish them easily. These results have a significant impact on continuous authentication-related research.
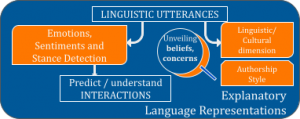 Sociolinguistic computing for detection of foreign influence:
Sociolinguistic computing for detection of foreign influence:
Foreign influence campaigns may attempt to inflict harm, often appealing to moral dimensions and identities, as a strategy to induce polarization in other societies. Our research explores potential indicators of influence attempts in language, for example, a sudden introduction of highly controversial and/or polarizing topics in online posts/messages. Language that reflects (and speaks to) the moral values of the target audience can increase in-group cohesion, but further contribute to polarization. Thus, social computing techniques leverage moral values expressed in language to enhance the detection of stances and concerns, as a step toward detection of influence and potentially harmful polarization.
Preference-aware Decision Making:

Humans excel at autonomy in their cognitive flexibility to make satisficing decisions in uncertain and dynamic environments. However, when designing autonomous systems, existing formal methods with Boolean truth of logical “correctness” fundamentally limit machines to achieve human-like intelligent planning that trades off between task completion, correctness, and preferences over alternative outcomes. FINS research on this matter focuses on developing new formal specification and methods for preference-based planning in uncertain environments. There are three key questions: How can a machine rigorously specify human’s preferences and temporal goals in formal logic? Given a task specific in this language, how can a machine synthesize policies to achieve preferred satisfaction of the mission in an uncertain environment? How can researchers enable an agent to adapt its preference-based policy while learning the human’s preference and the environment it interacts with?
Reverse Engineering for Integrated Circuits:

Integrated Circuit (IC) manufacturing leverages a global supply chain to maintain economic competitiveness. Modularization of the manufacturing workflow leaves it vulnerable to malicious attacks. For instance, untrusted foundries may deliberately install backdoors, i.e. hardware Trojans, into cyber systems for an adversary to exploit at will, or the circuit design–the IP of the designer–maybe stolen and duplicated. Reverse Engineering (RE) is the only approach for security experts to verify IC design, detect stolen IP, and, potentially, guarantee trust in the device. However, the existing RE process is ad-hoc, unscalable, error-prone, and requires manual intervention by subject matter experts, thereby limiting its potential as the go-to tool for hardware assurance.
This thrust currently focuses on resolving these limitations by developing critical algorithmic infrastructure to advance automation in the IC RE process. This project uses concepts from image processing, computer vision, ML, and AI to acquire, process, and gain insights from electron microscopy images of the IC and further develop AI-driven security policy for generating RE-compliant IC design for seamless cost/time-efficient design verification. The knowledge gained through this project will also be disseminating through educational programs and collaborations with the semiconductor industry.
Trustworthy AI:
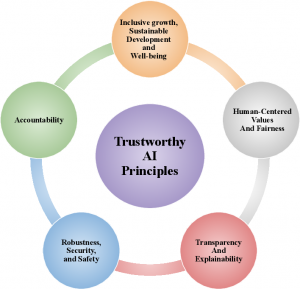
The why of AI. Artificial intelligence systems are continuing to grow in popularity for pulling useful predictions from complex data. However, as the decisions of these AI systems increase in their impact, we must decide just how much to trust those decisions. We study why models make their decisions and try to develop research that enables user trust of those decisions. The complexity of AI models make it non-trivial to understand exactly why a model may make mistakes, or even more subtly why a model might make the right decision for the wrong reasons. Reliable & Trustworthy AI research aims to build the necessary understanding and tools to provide solid answers to the rationale behind model predictions; when they are right, and more importantly, when they are wrong.